
Niniejszy artykuł przedstawia przegląd prac naukowych na temat oceny jakości Wikipedii w różnych językach. Pomimo faktu, że ta ogólnodostępna encyklopedia jest często krytykowana za niską jakość informacji, nadal pozostaje jedną z najpopularniejszych baz wiedzy na świecie. Obecnie Wikipedia znajduje się na 5 miejscu wśród najczęściej odwiedzanych witryn na świecie (po Google, YouTube, Facebook, Baidu). Artykuły w tej encyklopedii są tworzone i edytowane w około 300 różnych językach. Obecnie Wikipedia zawiera ponad 46 milionów artykułów dotyczących różnych tematów.
 Każdego dnia liczba artykułów w Wikipedii rośnie. Te artykuły mogą być tworzone i edytowane nawet przez anonimowych użytkowników. Autorzy nie muszą formalnie dekłarować swoich umiejętności, wykształcenia i doświadczenia w pewnych obszarach. Wikipedia nie ma centralnego zespołu redakcyjnego ani grupy recenzentów, którzy mogliby kompleksowo sprawdzać wszystkie nowe i istniejące teksty. Z tych i innych powodów ludzie często krytykują koncepcję Wikipedii, wskazując w szczególności na nizką jakość informacji.
Każdego dnia liczba artykułów w Wikipedii rośnie. Te artykuły mogą być tworzone i edytowane nawet przez anonimowych użytkowników. Autorzy nie muszą formalnie dekłarować swoich umiejętności, wykształcenia i doświadczenia w pewnych obszarach. Wikipedia nie ma centralnego zespołu redakcyjnego ani grupy recenzentów, którzy mogliby kompleksowo sprawdzać wszystkie nowe i istniejące teksty. Z tych i innych powodów ludzie często krytykują koncepcję Wikipedii, wskazując w szczególności na nizką jakość informacji.
Mimo to w Wikipedii można czasem znaleźć wartościowe informacje – w zależności od wersji językowej i tematyki. Praktycznie w każdej wersji językowej istnieje system nagród za najlepsze artykuły. Jednak istnieje bardzo niewiele takich artykułów (mniej niż jeden procent). W niektórych wersjach językowych istnieją również inne oceny jakości. Jednak przeważająca większość artykułów nie ma ocen (w niektórych językach ponad 99%).
Automatyczna ocena jakości artykułów Wikipedii
Tak więc, w Wikipedii wiele artykułów nie ma ocen jakości, zatem każdy czytelnik musi niezależnie analizować ich zawartość. Temat automatycznej oceny jakości artykułów Wikipedii w świecie naukowym nie jest nowy. Zasadniczo prace naukowe dotyczą najbardziej rozwiniętej wersji językowej Wikipedii – angielskiej, która zawiera już ponad 5,5 miliona artykułów. W swoich badaniach skupiam się na różnych wersjach językowe Wikipedii: angielska, polska, rosyjska, białoruska, ukraińska, niemiecka, francuska itd.
Od momentu założenia i wzrostu popularności popularności Wikipedii pojawia się coraz więcej publikacji naukowych na ten temat. Jedno z pierwszych badań wykazało, że pomiar objętości treści może pomóc w określeniu stopnia „dojrzałości” artykułu. Praca ta pokazuje, że lepsze teksty są długie, używają referencje w sposób spójny, edytowane przez setki autorów i mają tysiące edycji.
Jak dochodzą do takich wniosków? W uproszczeniu: trzeba porównać między sobą dobre i złe artykuły.
 Jak już wspomniano wcześniej, w prawie każdej wersji językowej Wikipedii istnieje system oceny jakości artykułów. Najlepsze artykuły są wyrózniany w specjalny sposób – otrzymują specjalną „odznakę”. W polskiej Wikipedii takie artykuły nazywają się „Artykuły na Medal” (ANM), w angielskiej Wikipedii – „Featured Articles”. Istnieje różnież inna „odznaka” dla artykułów, którym trochę „brakuje” do najlepszych – „Dobre artykuły” (DA) (w wersji angielskiej jest to „Good Articles”). W niektórych wersjach językowych istnieją inne szacunki dotyczące bardziej „słabych” artykułów. Na przykład w polskiej Wikipedii można jeszcze spotkać następujące oceny: Czwórka, Start, Załążek. W języku angielskim można znaleźć więcej: A-klasa, B-klasa, C-klasa, Start, Stub (Załążek). Już na przykładzie wersji angielskiej i polskiej można stwierdzić, że skala i standardy ocen się różnią w zależności od języka. Co więcej, nie wszystkie wersje językowe Wikipedii posiadają tak rozbudowany system oceny jakości artykułów jak angielska. Na przykład niemiecka Wikipedia, która zawiera ponad 2 miliony artykułów, używa tylko dwóch klas jakości – odpowiedników ANM i DA.
Jak już wspomniano wcześniej, w prawie każdej wersji językowej Wikipedii istnieje system oceny jakości artykułów. Najlepsze artykuły są wyrózniany w specjalny sposób – otrzymują specjalną „odznakę”. W polskiej Wikipedii takie artykuły nazywają się „Artykuły na Medal” (ANM), w angielskiej Wikipedii – „Featured Articles”. Istnieje różnież inna „odznaka” dla artykułów, którym trochę „brakuje” do najlepszych – „Dobre artykuły” (DA) (w wersji angielskiej jest to „Good Articles”). W niektórych wersjach językowych istnieją inne szacunki dotyczące bardziej „słabych” artykułów. Na przykład w polskiej Wikipedii można jeszcze spotkać następujące oceny: Czwórka, Start, Załążek. W języku angielskim można znaleźć więcej: A-klasa, B-klasa, C-klasa, Start, Stub (Załążek). Już na przykładzie wersji angielskiej i polskiej można stwierdzić, że skala i standardy ocen się różnią w zależności od języka. Co więcej, nie wszystkie wersje językowe Wikipedii posiadają tak rozbudowany system oceny jakości artykułów jak angielska. Na przykład niemiecka Wikipedia, która zawiera ponad 2 miliony artykułów, używa tylko dwóch klas jakości – odpowiedników ANM i DA.
Dlatego oceny w badaniach są często dzielone na dwie grupy:[1][2][3][4][5][6][7]
- Kompletne – oceny ANM i DA,
- Niekompletne – wszystkie inne
Nazwijmy tą metodę „binarną” (1 – kompletne artykuły, 0 – niekompletne artykuły). Taka separacja naturalnie „zaciera” granice między poszczególnymi klasami, ale pozwala budować i porównywać modele jakości dla różnych wersji językowych Wikipedii.
Data Mining
Do zbudowania takich model można użyć różnych algorytmów, w szczególności Data Miningu. W moich pracach często używam jednego z najbardziej powszechnych i skutecznych algorytmów – Random Forest[1][2][3][4][5][6][7] (Losowy las). Istnieją nawet badania[4], które porównują go z innymi algorytmami (CART, SMO, Multilayer Perceptron, LMT, C4.5, C5.0 itd.). Losowy las pozwala budować modele nawet przy użyciu niezależnych zmiennych, które są ze zobą skorelowane. Dodatkowo ten algorytm może pokazać, które zmienne są bardziej istotne dla określenia jakości artykułów. Jeśli potrzebujemy uzyskać inne informacje na temat znaczenia zmiennych, możemy użyć innych algorytmów, w tym regresja logistyczna[13].
Wyniki pokazują, że istnieją różnice pomiędzy modelami jakości artykułów w różnych wersjach językowych Wikipedii[1][2][3][4]. Zatem jeśli w jednej wersji językowej ważniejszym parametrem będzie liczba referencji (źródeł), w innym języku ważniejsza będzie liczba obrazów i długość tekstu.
Tak więc jakość jest modelowana jako prawdopodobieństwo przypisania artykułu do jednej z dwóch grup – Kompletnych lub Niekompletnych artykułów. Wniosek jest oparty na analizie różnych parametrów (czy też mierników): długości tekstu, liczby notatek, obrazów, przekrojów, linków do artykułu, liczby faktów[6], odwiedzin, liczby wydań i wielu innych. Istnieje również szereg parametrów językowych[5][7], które zależą od danego języka. Obecnie w badaniach wykorzystuje się w sumie ponad 300 parametrów, w zależności od wersji językowej Wikipedii i złożoności zbudowanego modelu. Niektóre parametry, takie jak referencje (źródła), można dodatkowo oceniać[14] – tj. można analizować nie tylko liczbę, ale także oceniać popularność i wiarygodność każdego źródła używanego w artykule w Wikipedii.
Gdzie można uzyskać te parametry?
Istnieje kilka źródeł – mogą to być kopie zapasowe Wikipedii, usługa API, narzędzia specjalne oraz inne[12]. W celu uzyskania niektórych parametrów, wystarczy wysłać zapytanie do odpowiedniego interfejsu API, w przypadku innych parametrów (szczególnie językowych) należy użyć specjalnych bibliotek i parserów. Jednak, znaczna część czasu poświęcana jest na pisanie własnych narzędzi (omówimy to w oddzielnych artykułach).
Czy istnieją inne sposoby oceny jakości artykułów innych niż binarne?
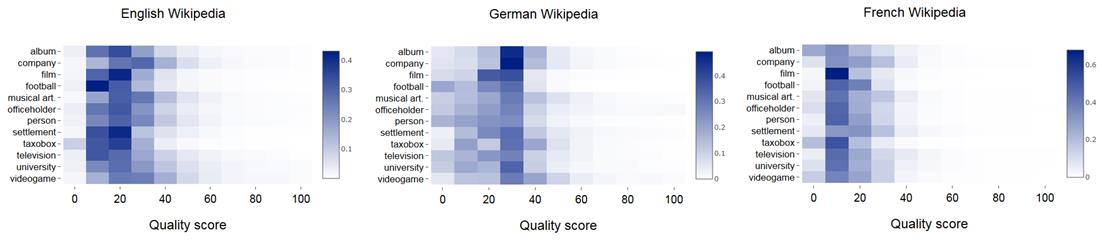
Tak. W ostatnich badaniach[8][9] zaproponowano metodę szacowania jakości artykułów w skali od 0 do 100 (jako zmienna ciągłą). Tzn. artykuł może zdobyć np. 45,78 pkt. Ta metoda została przetestowana na 55 wersjach językowych Wikipedii. Wyniki są dostępne w serwisie WikiRank, który pozwala ocenić i porównać jakość oraz popularność artykułów Wikipedii w różnych językach. Metoda ta oczywiście nie jest idealna, ale działa na znane lokalnie tematy[9].
Czy istnieją sposoby oceny jakości nie całego artykułu Wikipedii, a jego części?
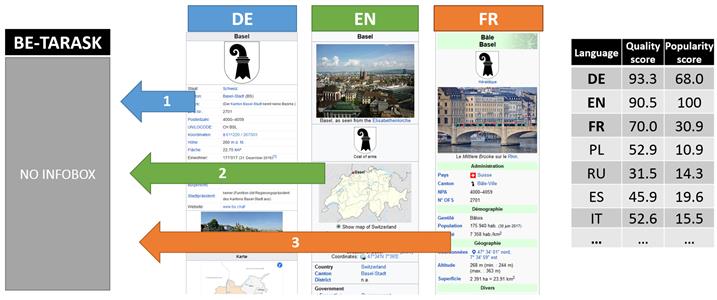
Oczywiście. Na przykład jednym z ważnych elementów tego artykułu jest tak zwany infoboks. Jest to osobna ramka (tabela), która często znajduje się w prawym górnym rogu artykułu i pokazuje najważniejsze fakty o podmiocie. Dlatego nie trzeba szukać tych informacji w tekście – wystarczy spojrzeć na tą ramkę. Niektóre badania są poświęcone ocenie jakości tych infoboksów[2][11]. Istnieją również projekty, takie jak Infoboxes, które umożliwiają automatyczne porównywanie infoboksów w różnych wersjach językowych Wikipedii.
Po co to wszystko?

 Wikipedię często czytają, ale nie zawsze sprawdzają jakość informacji. Proponowane metody mogą ułatwić to zadanie – jeśli artykuł jest zły, to użytkownik wiedząc o tym, będzie bardziej ostrożny w używaniu tych materiałów (np. do podjecia decyzji). Z drugiej strony użytkownik może również zobaczyć, w którym języku temat jest lepiej opisany. A co najważniejsze, nowoczesne techniki pozwalają na transfer informacji między różnymi wersjami językowymi. Oznacza to, że można automatycznie wzbogacić słabe wersje Wikipedii informacjami o wysokiej jakości z innych wersji językowych[10]. Poprawi to również jakość innych semantycznych baz danych, dla których Wikipedia jest głównym źródłem informacji. Przede wszystkim, to jest – DBpedia, Wikidata (Wikidane), YAGO2 i inni.
Wikipedię często czytają, ale nie zawsze sprawdzają jakość informacji. Proponowane metody mogą ułatwić to zadanie – jeśli artykuł jest zły, to użytkownik wiedząc o tym, będzie bardziej ostrożny w używaniu tych materiałów (np. do podjecia decyzji). Z drugiej strony użytkownik może również zobaczyć, w którym języku temat jest lepiej opisany. A co najważniejsze, nowoczesne techniki pozwalają na transfer informacji między różnymi wersjami językowymi. Oznacza to, że można automatycznie wzbogacić słabe wersje Wikipedii informacjami o wysokiej jakości z innych wersji językowych[10]. Poprawi to również jakość innych semantycznych baz danych, dla których Wikipedia jest głównym źródłem informacji. Przede wszystkim, to jest – DBpedia, Wikidata (Wikidane), YAGO2 i inni.
Źródło ilustracji – [8]
Bibliografia
- [1] Lewoniewski, W., Węcel, K., & Abramowicz, W. (2016). Quality and Importance of Wikipedia Articles in Different Languages. In International Conference on Information and Software Technologies (pp. 613-624). Springer International Publishing. DOI: 10.1007/978-3-319-46254-7_50
- [2] Węcel, K., & Lewoniewski, W. (2015). Modelling the quality of attributes in Wikipedia infoboxes. In International Conference on Business Information Systems (pp. 308-320). Springer International Publishing. DOI: 10.1007/978-3-319-26762-3_27
- [3] Lewoniewski, W., Węcel, K., & Abramowicz, W. (2015). Analiza porównawcza modeli jakości informacji w narodowych wersjach Wikipedii. Prace Naukowe/Uniwersytet Ekonomiczny w Katowicach, 133-154.
- [4] Lewoniewski, W., Węcel, K., Abramowicz, W. (2017), Analiza porównawcza modeli klasyfikacyjnych w kontekście oceny jakości artykułów Wikipedii, Matematyka i informatyka na usługach ekonomii, Wydawnictwo UEP Poznań, ISBN 9788374179386
- [5] Khairova, N., Lewoniewski, W., & Węcel, K. (2017). Estimating the quality of articles in Russian Wikipedia using the logical-linguistic model of fact extraction. In International Conference on Business Information Systems (pp. 28-40). Springer, Cham. DOI: 10.1007/978-3-319-59336-4_3
- [6] Lewoniewski, W., Khairova, N., Węcel, K., Stratiienko, N., & Abramowicz, W. (2017). Using Morphological and Semantic Features for the Quality Assessment of Russian Wikipedia. In International Conference on Information and Software Technologies (pp. 550-560). Springer, Cham. DOI: 10.1007/978-3-319-67642-5_46
- [7] Lewoniewski, W., Wecel, K., & Abramowicz, W. (2017). Determining Quality of Articles in Polish Wikipedia Based on Linguistic Features. DOI: 10.20944/preprints201801.0017.v1
- [8] Lewoniewski, W., Węcel, K., & Abramowicz, W. (2017). Relative Quality and Popularity Evaluation of Multilingual Wikipedia Articles. In Informatics (Vol. 4, No. 4, p. 43). Multidisciplinary Digital Publishing Institute. DOI: 10.3390/informatics4040043
- [9] Lewoniewski, W., & Węcel, K. (2017). Relative quality assessment of Wikipedia articles in different languages using synthetic measure. In International Conference on Business Information Systems (pp. 282-292). Springer, Cham. DOI: 10.1007/978-3-319-69023-0_24
- [10] Lewoniewski, W. (2017). Enrichment of Information in Multilingual Wikipedia Based on Quality Analysis. In International Conference on Business Information Systems (pp. 216-227). Springer, Cham. DOI: 10.1007/978-3-319-69023-0_19
- [11] Lewoniewski, W. (2017). Completeness and Reliability of Wikipedia Infoboxes in Various Languages. In International Conference on Business Information Systems (pp. 295-305). Springer, Cham. DOI: 10.1007/978-3-319-69023-0_25
- [12] Lewoniewski, W., Węcel, K., (2017), Cechy artykułów oraz metody ich ekstrakcji na potrzeby oceny jakości informacji w Wikipedii. Studia Oeconomica Posnaniensia 12/2017. DOI: 10.18559/SOEP.2017.12.7
- [13] Lamek, A., Lewoniewski, W. (2017), Zastosowanie regresji logistycznej w ocenie jakości informacji na przykładzie Wikipedii. Studia Oeconomica Posnaniensia 12/2017. DOI: 10.18559/SOEP.2017.12.3
- [14] Lewoniewski, W., Węcel, K., Abramowicz, W., (2017), Analysis of References across Wikipedia Languages. Information and Software Technologies. ICIST 2017. DOI: 10.1007/978-3-319-67642-5_47
Źródło: Wykop.pl